oMLX 与 OpenClaw 组合解析:Apple Silicon 本地 AI Agent 部署方案
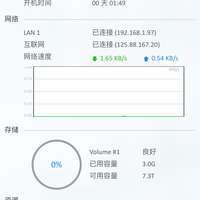
随着 Apple Silicon 性能的提升,在本地运行大模型推理已成为技术趋势。oMLX 作为专为 Apple Silicon 设计的本地推理服务器,配合开源 AI Agent 框架 OpenClaw,提供了一套无需云端 API 的本地化解决方案。该组合通过硬件加速与优化的缓存机制,旨在解决本地推理中的延迟与上下文管理问题。01技术架构与核心特性oMLX 并非简单的模型运行工具,其核心优势在于针对 AI Agent 工作流进行了底层优化。AI Agent 在执行任务时,往往需要频繁回溯之前的对话上下文。传统推理方式通常需要重新计算这些上下文,导致耗时增加。oMLX 引入了 SSD 缓存机制,将计算过程中的中间状态写入磁盘,当需要回溯时直接从 SSD 读取,实现了毫秒级的上下文恢复速度。SSD 缓存机制将推理计算缓存写入 SSD,上下文回溯无需重新计算,显著降低延迟。连续批处理支持多个请求同时处理,无需排队,提升并发处理能力。视觉语言模型支持除文本外,支持图片理解任务的本地推理。菜单栏管理集成于 Mac 系统菜单栏,提供可视化的模型管理与控制界面,无需依赖命令行。模型目录复用自动识别并...
OpenClaw 本地部署策略:从 Cloud 模型验证到本地模型运行
随着 OpenClaw 在 2026 年获得更多关注,用户关于如何实现“低成本 AI 助手”的讨论日益增多。通过 Ollama,OpenClaw 确实可以实现“本地优先”的使用方式,但要想实现高效且尽可能零费用的运行,关键在于正确区分模型的使用方式。并非所有通过 Ollama 调用的模型都是纯本地离线模型,搞清楚“Cloud 模型”与“本地模型”的区别,是制定部署策略的第一步。01核心概念:两类模型的本质区别OpenClaw 通过 Ollama 使用的模型主要分为两类,它们在部署成本、硬件要求和运行机制上有显著差异。准确识别这两类模型,有助于避免对“零费用”概念的误解。对比维度Cloud 模型本地模型模型代表kimi-k2.5:cloud, qwen3.5:cloud, glm-5:cloud, minimax-m2.7:cloudqwen3:14b, qwen3.5:9b权重存储云端服务器本地磁盘下载安装硬件压力较小,启动轻便较大,占用内存/显存部署门槛低,无需下载大文件较高,需解决硬件兼容性适用场景快速验证、流程测试数据隐私、长期低成本、离线运行OpenClaw 两类模型特性对比0...